목표 : [오전] 머신러닝 군집(Clustering)_세션
[오후] 머신러닝_과제 제출
ML_비지도학습_군집분석(Clustering)
ㅇ 정의 : 피쳐(컬럼) 유사성의 개념을 기반으로 전체데이터셋을 그룹으로 나누는 그룹핑 기법 (각 그룹 = 클러스터)
ㅇ 프로세스
1. 전처리 pre-processing
1) 기간 설정 : 통상적으로 3개월~1년의 data. 그러나 목적과 의도에 따라 유연하게 대처 (but, 1주일은 무리!)
2) 이상치 기준설정 및 제거 : 다양하게 사용해보고 비교하기
. Z-Score
- 데이터의 분포가 정규 분포를 이룰 때, 데이터의 표준 편차를 이용해 이상치를 탐지
- 각 데이터(행) 마다 Z-score 를 구합니다. Z(표준점수) 값은 X에서 평균을 뺀 데이터를 표준편차로 나눈 값
- 표준 점수는 평균으로부터 얼마나 멀리 떨어져 있는지를 보여준다. 일반적으로 -3에서 3 사이의 값이며, 그 외에는 이상치로 간주
. IQR
- 데이터의 분포가 정규 분포를 이루지 않을 때 사용
- 데이터의 25% 지점과 75% 지점 사이의 범위를 사용하며 그 외의 값을 모두 이상치로 간주.

. Isolation Forest
- 머신러닝 기법 중 하나로, 컬럼 갯수가 많을 때 이상치 판별이 용이
- 데이터셋을 결정트리 형태로 표현
- 한 번 분리될 때 마다 경로 길이가 부여되며, 트리에서 몇 번을 분리해야 하는지 (데이터까지의 경로 길이)를 기준으로 데이터가 이상치인지 아닌지를 판단
- 즉 이상치는 다른 관측치에 비해 짧은 경로 길이를 가진 데이터
- 경로 길이로 점수는 0 에서 1 사이로 산출되며, 결과가 1 에 가까울수록 이상치로 간주
- 각 값은 매, 펭귄, 돌고래, 곰 중 하나에 배치됨
- 그러나 이상치의 경우, 이 어디에도 속하지 않을 확률이 높음
. DBScan
- 밀도 기반의 클러스터링 알고리즘으로 어떠한 클러스터에도 포함되지 않는 데이터를 이상치로 탐지하는 방법으로 복잡한 구조의 데이터에서 이상치를 판별하는 데 유용
- 주로 지리 데이터 분석, 이미지 데이터 분석의 이상치 기법으로 사용
- 각 데이터의 밀도를 기반으로 군집을 형성시키고 설정된 거리 내에 설정된 최소 개수의 다른 포인트가 있을 경우, 해당 포인트는 핵심 포인트로 간주됨
- 핵심 포인트들이 서로 연결되어 군집을 형성하며, 이와 연결되지 않은 포인트는 이상치로 분류.
3) 표준화: 표준화를 한다고 항상 성능이 좋아지지 않음. 그러나 데이터의 크기가 너무 크거나 컬럼간 데이터 range 차이가 많을 때는 해야 함(필수는 아니나 프로젝트엔 써보면 좋을듯)
. minmax scale (이상치에 약해서 거의 사용안함)
: 모든 데이터 값을 0과 1 사이에 배치. 데이터 내, 큰 값이 있다면 나머지 값들은 0에 수렴하므로 이상치에 약함
. standard scale
: 평균을 0, 표준편차를 1로 변환. minmax의 한계점을 보완. 평균으로부터 얼마나 많이 떨어져있는지를 봄.
군집화에서 가장 많이 쓰이는 표준화기법
4) 차원 축소(PCA) - 필수
: 차원 축소는 많은 컬럼으로 구성된 다차원 데이터 세트의 차원을 축소해 새로운 차원의 데이터 세트를 생성하는 방법. 그중 PCA는 대표적인 차원축소로 상관관계를 이용해서 데이터 분포를 가장 잘 표현하는 성분을 찾아줌!
PCA 기법의 핵심은 가장 높은 분산을 가지는 데이터의 축을 찾아 그 축으로 차원을 축소하는 것인데, 이 축을 주성분이라 명
2. 프로세스(Experiment)
5) K값(군집갯수), 초기 컬럼(피쳐) 선정
파이썬에서 알려주는 기법들(실루엣 분석 등 3가지)은 참고치일 뿐, 절대치가 아님. 회사나 분석가의 선택
. 실루엣 분석(Silhouette Coefficient)
: 실루엣 계수는 -1~1사이의 값을 갖고, 0에 가까울 수록 근처 군집과 가깝고 -1이나 1에 가까울수록 근처 군집과 멀리 떨어져있고, 유의미함
. scree plot의 elbow-point
: yellow brick library의 elbow method를 사용하 알고리즘이 군집이 나뉘는 시간까지 고려한 K값 도출
. Distance Map
: 군집 간 거리를 시각화 해주는 기법입니다. 이는 실행마다 다르게 보여질 수 있습니다.
6) k-means clustering 시행: 데이터를 거리기반 K개의 군집(Cluster)으로 묶는(Clusting) 알고리즘. K-means 알고리즘에서 K는 묶을 군집(클러스터)의 개수를 의미한다. 즉 '각 군집의 평균(mean)을 활용하여 K개의 군집으로 묶는다'는 뜻
- 알고리즘
- 군집 수 K 설정
- 초기 중심점 K개 설정
- 중심점을 기준으로 data point 들의 거리를 비교하고, 더 가까운 중심점에 군집할당
- 할당된 점들의 의 중심점 위치 조정됨
- 중심점의 위치가 변하지 않을때까지 반복
7) 군집 분포 확인 - 필수
- 데이터셋을 기반으로 데이터가 잘(얼마나 밀도있게) 나뉘었는지 확인하는 과정
- 컬럼과 k값을 조정해가며 명확한 군집분포를 도출(좌→우)
- 각각의 data point 가 충돌하지 않도록 실험을 반복
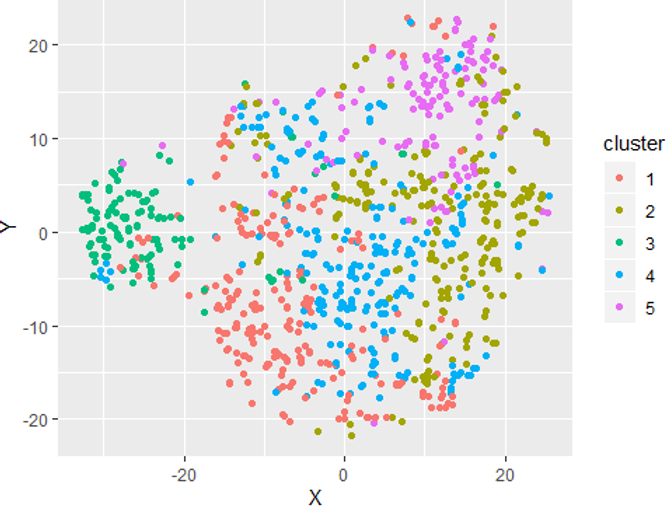
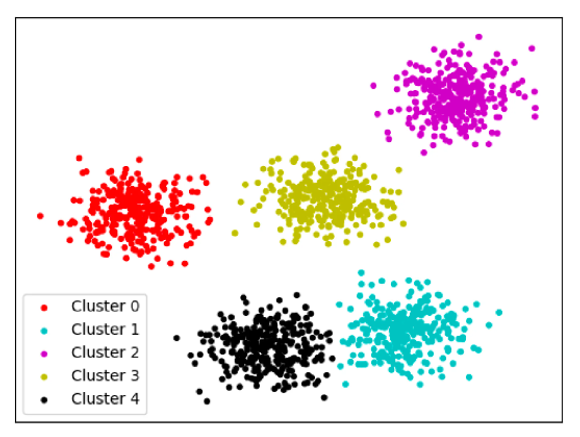
8) 2~7번을 반복하며 최적의 결과 도출
. 통계지식 매몰을 지양하며 분석가의 주관 개입이 필수
. 컬럼 내, 결측이 50%가 넘는 경우 사용하지 않음
. 결측은 아니나 value가 0이 많은지
. 데이터 전반의 분포, 컬럼 간의 상관계수 체크
. 데이터가 불규칙한지
. (분석가)컬럼이 가지는 개념적인 의미를 생각하고 진행하기
. 컬럼값이 이진형인지 (왠만하면 사용하지 않는 것이 좋음)
. 클러스터 비중이 지나치게 편향되어 있는지(너무 하나의 그룹에 편향되어있는지? 절반이상은 다시)
9~11은 심화프로젝트에 필수는 아님
9) 모델링 : 클러스터링 결과를 가지고 이를 모델에 학습
10) 데이터 적재 및 자동화 설정
- cluster 별로 나뉜 고객들을 별도 테이블에 저장
- 스케줄 기능을 통해, '주기 별로 라이브한 데이터를 자동 테이블 적재하는 것'까지가 클러스터링의 최종 작업
11) 인사이트 도출
다음 목표 : 프로젝트 Data 잘 고르기!!!
'회고 > 내배캠_데이터분석가_'24.04~08' 카테고리의 다른 글
| Chapter 3. 데이터 분석 입문 (10주차_2/5) (0) | 2024.06.18 |
|---|---|
| Chapter 3. 데이터 분석 입문 (10주차_1/5) (0) | 2024.06.18 |
| Chapter 3. 데이터 분석 입문 (9주차_3/5) (1) | 2024.06.13 |
| Chapter 3. 데이터 분석 입문 (9주차_2/5) (0) | 2024.06.12 |
| Chapter 3. 데이터 분석 입문 (9주차_1/5) (0) | 2024.06.10 |