[목표]
- 다양한 데이터의 종류
- 편차, 분산, 표준편차
- 표본분포화 히스토그램
- 신뢰구간과 정규분포
1. 데이터의 종류
ㅇ 데이터를 분류하는 이유?
- 데이터 유형에 따라 시각화, 해석, 통계모델 결정에 중요한 역할을 하기 때문!
| 데이터 종류 | 개념 | 예시 | |
| 수치형 | 수치형 | 숫자를 이용해 표현할 수 있는 데이터. 이산형, 연속형 을 모두 포함하는 개념 | 체중, 신장, 사고건수, 일 방문자수 |
| 연속형 | 일정 범위 안에서 어떤 값이든 취할 수 있는 데이터 | 체중, 신장 | |
| 이산형 | 횟수와 값은 정수형 값만 취할 수 있는 데이터 즉, 소수점의 의미가 없는 데이터를 의미(수치형 데이터와의 차이점) |
사고 건수, 일 방문자수 |
|
| 범주형 | 범주형 | 가능한 범주 안의 값만을 취하는 데이터 (값이 달라짐에 따라 좋거나 나쁘다고 할 수 없음) 명목형 이진형, 순서형 을 모두 포함하는 개념 | 나라, 도시, 혈액형, 성별, 성공여부, 등수 |
| 명목형 | 각 값이 서로 다른 범주를 나타내며, 순서나 크기의 의미를 갖지 않음 | 혈액형, 성별 | |
| 이진형 | 두개의 값만을 가지는 범주형 데이터의 특수한 경우 e.g. 0,1 / 예,아니오 / 참,거짓 |
성별, 성공여부 | |
| 순서형 | 값들 사이에 분명한 순위가 있는 데이터 | 등수 | |

2. 편차, 분산, 표준편차, 표본분포
ㅇ 대푯값 ▷ 데이터의 'WHERE (어디에 존재하는가)'를 표현하는 개념
- 평균 : 모든 값의 총합을 개수로 나눈 값
- 중앙값 : 데이터 중 가운데 위치한 값
- 최빈값 : 데이터 중 가장 많이 도출된 값
# 평균
df['컬럼'].mean()
# 중앙값
df['컬럼'].median()
# 최빈값
df['컬럼'].mode()
ㅇ 편차, 분산, 표준편차 ▷ 데이터의 'HOW (어떻게 존재하는가)'에 대한 개념
- 편차(deviation) : 하나의 값에서 평균을 뺀 값. 평균으로부터 얼마나 떨어져 있는지를 의미 / x - 평균값
- A 학생의 영어점수: 30점
- B 학생의 영어점수: 70점
- C 학생의 영어점수: 80점
- A,B,C 학생의 평균 영어점수: 60점
> A 학생의 편차: -30
> B 학생의 편차: +10
> C 학생의 편차: +20
학생 전체의 편차를 나타내기 위해 각 학생들의 편차를 모두 더하면 0이 산출됨.
따라서 편차로는 반 전체의 점수 분포를 정확히 알 수가 없기에 나온 개념이 '분산'.
- 분산(variance) : 편차의 합이 0으로 나오는 것을 방지하기 위해 만들어진 개념. (편차 제곱합의 평균)
- A 학생의 편차 제곱: (-30)^2 = 900
- B 학생의 편차 제곱: (+10)^2 = 100
- C 학생의 편차 제곱: (+20)^2 = 400
> 편차 제곱합: 1400
> 편차 제곱합의 평균(분산): 1400/3 = 466
분산은 466이 도출. 그러나 점수라는 값에 제곱이 들어가며(점수에 제곱..!) 그 단위가 달라지게 됨.
따라서 실제 데이터가 어느 정도로 차이가 있는지 알기 어려움.
이를 해결하기 위해 도입된 개념이 '표준편차'.
- 표준편차 : 분산에 제곱근을 씌워준 값 (원래 단위로 되돌리기! = standard deviation(σ))
- 분산: 466
- 분산의 제곱근 = 표준편차 = 약 21.5870331449
이것으로 우리는 '반의 영어점수가 약 20만큼 분산되어 있다'라는 해석이 가능하다.
ㅇ 모집단, 표본, 표본분포 ▷ 양질의 데이터를 기반으로 효과적인 통계분석하기 위해 표본을 추출
- 모집단: 어떤 데이터 집합을 구성하는 전체 대상
- 표본: 모집단 중 일부. 모집단의 부분집합

- 표본분포: 표본의 분포. 표본이 흩어져 있는 정도. 표본통계량으로부터 얻은 도수분포
- 표본평균의 분포: 모집단에서 여러 표본을 추출하고 각 표본의 평균을 계산한다면, 이는 중심극한정리에 따라 정규분포에 가까워진다. 이는 표본 크기가 충분히 크다면 어떤 분포에서도 표본 평균이 정규분포를 따른다는 것을 의미.
- 표본분산의 분포: 모집단에서 여러 표본을 추출하고 각 표본의 분산을 계산한다면, 이 표본분산들의 분포는 카이제곱 분포(다음강의에서 설명)를 따른다. 이는 모집단이 정규분포를 따를 때 보다 높게 성립된다.
- 표준오차: 표본의 표준편차. = 표본평균의 평균과 모평균의 차이
▶ 모집단에서 표본을 추출하고, 이를 시각화하여 통계적 의미를 찾기 위해서는 하기 개념을 알아야 함.
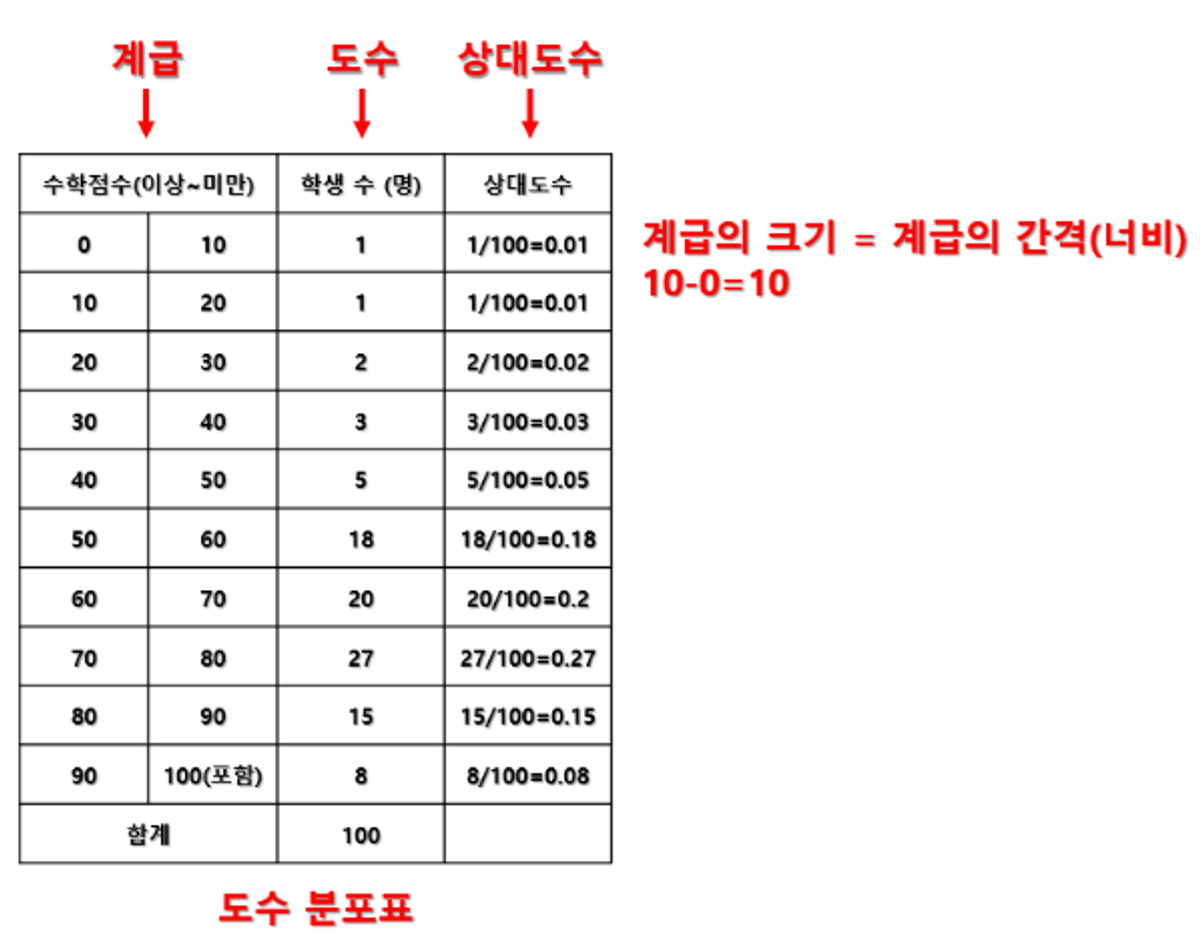
- 도수: 특정 구간에 발생한 값의 수
- 상대도수: 특정 도수를 전체 도수로 나눈 비율
- 도수분포표: 각 값에 대한 도수와 상대도수를 나타내는 표
- 히스토그램: 도수분포표를 활용하여 만든 막대그래프
- 임의표본추출: 무작위로 표본을 추출하는 것
- 편향: 한쪽으로 치우쳐져 있음
- 도수분포표 만들기(선택)
|
순서
|
내용
|
|
1
|
최댓값, 최솟값 계산
|
|
2
|
최댓값, 최솟값을 포함하여 데이터를 특정 범위(계급)으로 나눔
|
|
3
|
각 계급을 대표하는 수치(계급값) 정하기
|
|
4
|
각 계급에 포함된 데이터 개수(도수)를 카운트
|
|
5
|
각 계급의 도수가 전체에서 차지하는 비율(상대도수)을 계산
|
|
6
|
특정 계급까지의 도수를 모두 합한다. (누적도수)
|
3. 정규분포, 신뢰구간
ㅇ 정규분포
앞에서 언급한 중심극한정리를 보면,
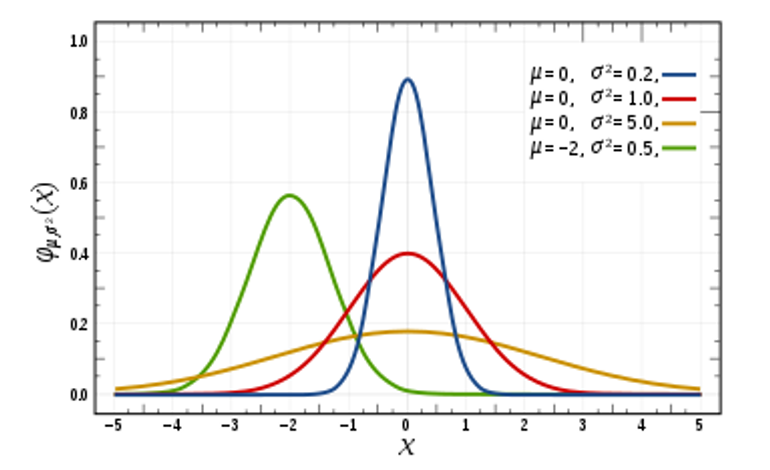
표본을 선정할 때 그 경우의 수는 매우 많을 것이고, 그것들을 평균 내어 모아보면 아래와 같은 종 모양의 분포를 띄는데,
이것이 정규분포이며, 특징은 아래와 같다.
- 분포는 좌우 대칭의 형태이며 평균치에서 가장 그 확률이 높다
- 곡선은 각 확률값을 나타내며, 모두 더하면 1이 된다
(동전을 뒤집어서 앞면이 나올 확률은 2분의 1 + 뒷면이 나올 확률 2분의 1 = 전체 확률 1)
- 정규분포는 평균과 분산(퍼진정도)에 따라 다른 형태를 가진다 (분산이 가장 큰 것은 노랑 그래프)
- 평균 0, 분산 1을 가지는 경우, 이를 '표준정규분포'라고 명명. (그림의 붉은색 그래프)
ㅇ 표준정규분포를 학습해야 하는 이유(표준화 이유)
- 위의 그래프와 같이 각각의 그래프는 평균과 분산값에 따라 다르게 그려질 수 있음
- 그럴 경우, 확률을 계산할 때 어려움
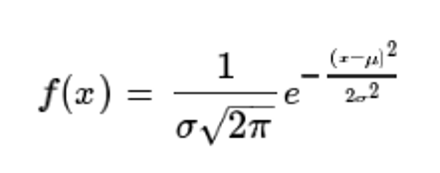
- 이를 통일하기 위해 분포의 평균과 분산 값을 통일하는 작업을 하는데, 이것이 표준화.
* 표준화 종류 : Z-score 표준화 (Standardization), Min-Max 스케일링 (Min-Max Scaling), Robust 스케일링
- 표준화 공식 : 확률변수 X에서 평균 m을 빼고 표준편차로 나누기!
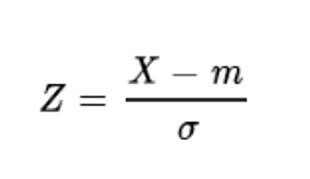
- 데이터분석 시 표준화가 필요한 경우: 머신러닝 모델을 만들 때, 데이터의 범위가 많이 차이나는 경우
1) 머신러닝 진행 시, 아래와 같이 두 컬럼 간의 '1'은 전혀 다른 의미를 가짐에도 같게 받아들이고 처리할 수 있음
2) 범위가 큰 데이터의 경우 숫자가 가지는 절대치를 잘못 받아들일 수 있음
> 이 경우 표준화를 반드시 해야 함!!
|
컬럼
|
Data Range
|
|
최근 일주일 접속일수
|
0~7
|
|
결제 금액
|
0~10000000000(100억)
|
ㅇ 신뢰구간, 신뢰수준
- 신뢰구간: 특정 범위 내에 값이 존재할 것으로 예측되는 영역. (영어점수가 10점에서 90점 사이일 것 같아요)
- 신뢰수준: 실제 모수를 추정하는데 몇 퍼센트의 확률로 신뢰구간이 실제 모수를 포함하게 되는 확률.
주로 95%와 99% 를 이용. (영어점수가 10점에서 90점 사이일에 분포할 확률이 95% 같아요)
import scipy.stats as st
import numpy as np
#샘플 데이터 선언
sample1 = [5, 10, 17, 29, 14, 25, 16, 13, 9, 17]
sample2 = [21, 22, 27, 19, 23, 24, 20, 26, 25, 23]
df = len(sample1) - 1 # 자유도 : 샘플 개수 - 1
mu = np.mean(sample1) # 표본 평균
se = st.sem(sample1) # 표준 오차
# 95% 신뢰구간 ( = 95% 신뢰하려면 데이터의 범위가 어떻게 되는지?)
st.t.interval(0.95, df, mu, se) # (10.338733110887336, 20.661266889112664)
# 99% 신뢰구간( = 99% 신뢰하려면 데이터의 범위가 어떻게 되는지?)
# 99% 로 신뢰할 수 있어야 하므로, 앞선 95% 보다 데이터 범위가 넓음
st.t.interval(0.99, df, mu, se) # (8.085277068873378, 22.914722931126622)
<요약>
ㅇ python은 데이터의 종류에 따라 관련된 계산을 어떤 식으로 수행할지 결정한다.
ㅇ 데이터 종류 : 수치형, 범주형 데이터
ㅇ 데이터 대푯값 : 평균, 중간값, 최빈값
데이터 분포를 보다 명확히 파악하기 위해 편차, 분산, 표준편차를 학습.
ㅇ 편차는 그 합이 0으로 분포를 확인 불가능.
→ 음수값을 없애기 위해 제곱을 취해주는 분산의 개념이 도입.
→ 분산은 제곱값으로 그 단위가 달라, 제곱근의 씌워 다시 단위를 맞춘 것이 표준편차.
ㅇ 무수히 많은 데이터를 대상으로 효과적인 통계분석을 위해 표본추출이 이루어짐.
ㅇ 모집단은 어떤 데이터 집합을 구성하는 전체이고, 표본은 그중 일부(부분집합).
ㅇ 표본의 분포를 가지고 모집단의 분포를 추정하며, 해당 과정에서 무수히 많은 경우의 수의 표본이 생성될 수 있음. 표본 크기가 충분히 크다면 어떤 분포에서도 표본평균이 정규분포를 따른다는 것이 중심극한정리.
ㅇ 정규분포는 종 모양을 띄고 있으며, 분포는 좌우 대칭의 형태. 평균치에서 그 확률이 가장 높음.
ㅇ 정규분포에서 평균 0, 분산 1을 가지는 경우, 이것이 표준정규분포.
데이터분석 시 이를 표준화라 명명.
ㅇ 데이터분석시 표준화가 필요한 경우: 머신러닝 모델을 만들 때, 데이터의 범위가 많이 차이나는 경우. 예시로 최근 일주일 접속일 수의 1과 결제금액의 1 은 같은 의미가 아니며, 범위가 큰 데이터의 경우 숫자가 가지는 절대치를 잘못 받아들일 수 있어 표준화는 반드시 필요.
'[분석] 통계' 카테고리의 다른 글
| [세션] 통계학 라이브세션_2회차 (1) | 2024.06.05 |
|---|---|
| [강의] 통계학_기초(1) (0) | 2024.05.31 |