[목표]
- 데이터의 통계적 실험을 이해
- 대표적인 통계적 실험인 A/B 테스트 이론을 학습
- 이를 해석하기 위한 통계적 지식을 학습
- 통계적 유의성, t검정, 카이제곱검정을 이해
- 이를 python 코드로 작성하며 활용
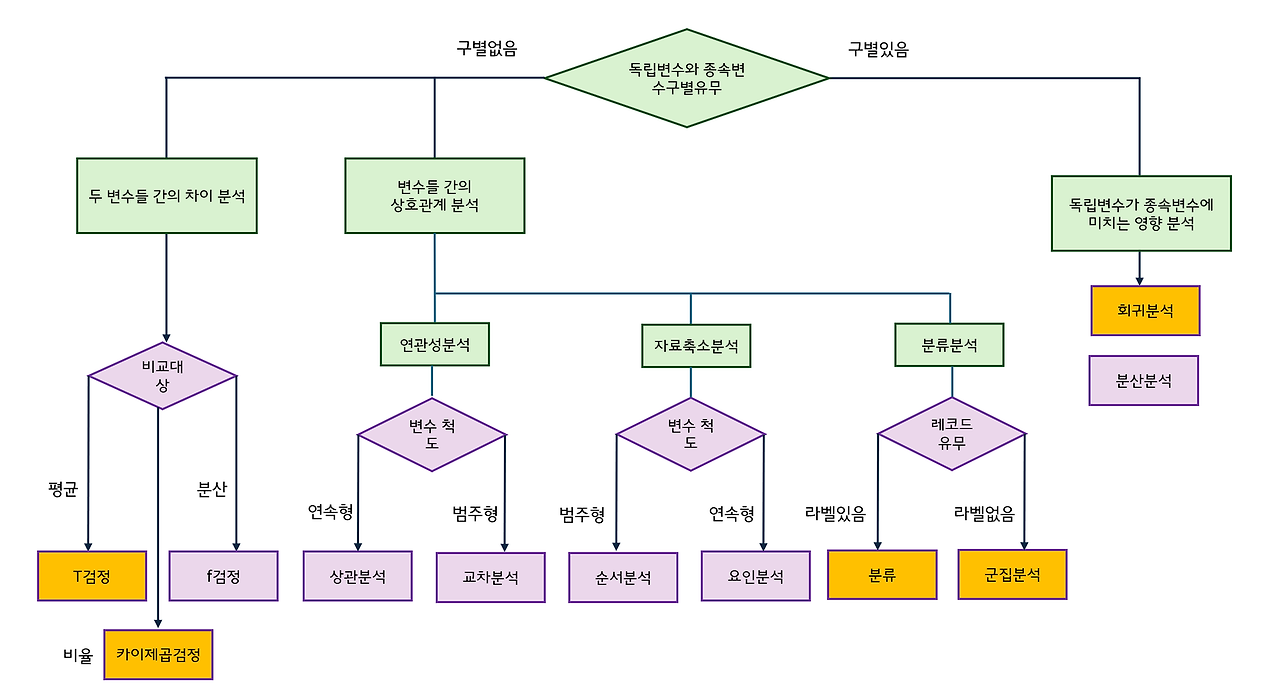
1. 데이터 분석가의 통계적 실험
ㅇ 통계적 실험
- 정의
• 어떤 목적을 가지고 관찰을 통해 측정값을 얻어내는 것
- 목적
• 통계적 추론을 통해 보다 진실에 가까운 값을 도출하기 위함
———————————————————————————————————
▷ 제한된 환경에서의 관찰을 통해 확보된 사실을 바탕으로 제한된 결론을 내리고, 확률적 판단으로 제한된 결론을 내려 진실에 가까운 값 도출
▷e.g. 모든 까마귀는 검정색이다. → 모든 까마귀가 검정색이 아닐 수도 있다 → 하지만 전 세계에 있는 까마귀를 모두 확인하는 것은 불가능 → 통계적 추론 실시 →진실에 가까운 값 도출
- 프로세스
• 가설 수립 → 실험 설계 → 데이터 수집 → 추론 및 결론의 도출
ㅇ 중심 학습 내용
2. A/B TEST (비즈니스 마케팅 시 필수!!)
- 개념
: 마케팅 고객데이터 분석 중 가장 널리 사용되는 방법으로 두 가지 처리 방법 중 어떠한 쪽이 더 좋다는 것을 입증하기 위해 실험군을 두 그룹으로 나누어 진행하는 실험
( ≒ 과학의 대조실험 (가정 입증을 위한 대조군, 실험군))

- 목적
. UI/UX 개선: 서비스에 진입한 방문자의 니즈에 알맞게 UI, UX 가 친절하지 않은 경우 이탈할 가능성 多
(e.g. 구매버튼을 찾기 어렵구나!)
. 전환율 증가: AB 테스트를 통해 무엇이 효과가 있는지 파악하면 전환율 상승에 도움
(e.g. c배너보다 d 배너의 전환이 더 좋구나!)
. 매출 증가: AB 테스트를 통해 UX가 개선되면 전환율이 상승할 뿐만 아니라, 브랜드에 대한 고객 충성도도 높아진다.
이는 곧 반복 구매로 이어져 매출 증가에 영향을 미치게 됨!
▷ 웹/앱 서비스의 광고 및 UI, UX의 ROI(투자 대비 수익) 상승. 즉 최소 투자로 최대 이익을 창출하고자 하는 것
- 버킷테스트, 분할 테스트라고도 불림.
- 기업들도 자체 툴을 만들어 운영하는 추세 (e.g. 당근, 토스)
- 종종 두 가지 처리 방법 중 하나는 기준이 되는 기존 방법이거나 아예 아무러 처리도 적용하지 않는 방법이 될 수 있음
- 주요 지표
. 서비스의 가입율
. 재방문율
. CTR(노출 대비 클릭율)
. CVR(클릭 대비 전환율, 구매전환율)
. ROAS(캠페인 비용 대비 캠페인 수익)
. eCPM(1,000회 광고 노출당 얻은 수익)
※ 통상 TEST그룹과 CONTROL그룹으로 나누지만 꼭 2개의 그룹으로 나눌 필요는 없음!
ㅇ 프로세스 (구분방법은 많지만 아래 내용은 꼭 알아두기!)
1) 현행 데이터 탐색
• 앞서 살펴본 주요 지표를 기준으로 현재 데이터 탐색
2) 가설 설정
• 비즈니스 목표를 달성하는 데 필요한 KPI를 정의 (서비스에 따라 매출이나 내방유도가 될 수 있음)
• KPI 전환율을 증가를 위한 귀무가설, 대립가설을 설정
• 귀무가설
◦ 통계학에서 처음부터 버릴 것을 예상하는 가설
◦ 차이가 없거나 의미 있는 차이가 없는 경우의 가설
◦ "새로운 광고배너를 게재해도 기존과 차이가 없을 것이다"
• 대립 가설
◦ 귀무가설에 대립하는 명제
◦ "새로운 광고배너를 게재해도 기존과 차이가 있을 것이다(다를 것이다)"
3) 유의 수준 설정 (오류 허용 수준 설정)
• 귀무가설이 맞을 때 오류를 얼마나 허용할 것인지 기준을 정하는 단계
(얼마나 오류를 허용할 것인지, 즉 신뢰도의 확률을 정함. e.g. 신뢰도 95% 일 경우 유의 수준(오차율)은 5%)
4) 테스트 설계 및 실행
• 사용자를 대조군과 실험군의 두 그룹으로 분리
• 대조군 그룹에게는 제품이나 서비스의 현재 버전을 보여주고, 실험군 그룹에게는 새 버전을 노출 처리
5) 테스트 결과 분석
• 측정 항목(가설)에 대해 두 그룹의 결과를 분석 (검정통계량 분석)
• 통계적 방법으로 결과를 분석하여 대조군과 실험군 사이의 통계적으로 유의미한 차이가 있는지 확인
- 주의사항
. 적절한 표본 크기 : 표본의 크기가 충분하지 않으면 유의미한 결과를 얻을 수 없음.
적절한 표본 크기를 결정하고, 그에 맞는 시간과 자원을 투자해야 함
. 하나의 변수만 변경 : 2개 이상 변경할 경우 어떤 변수가 영향을 미쳤는지 정확한 파악이 불가
. 무작위성 : 특정 타겟 유저를 통한 테스트는 의미가 없음. 무작위로 선택된 사용자들에게 각각 다른 변수를 적용해야 함
. 적절한 분석 방법 : A/B테스트 결과를 해석할 때는 가설 검증을 위한 통계적 분석 방법을 선택하고, 유의 수준을 설정해야 함
. 테스트 결과 의미 해석 : A/B테스트 결과가 통계적으로 유의미하더라도 항상 실제로 의미 있는 결과인지 한번 더 검증필요
. 정해진 기간 동안 진행 : 너무 짧으면 결과 수집이 어렵고, 너무 길면 사용자 행동이 변할 가능성 있음.
특히 너무 빈번하게 되면 고객 이탈의 요인이 될 수 있음
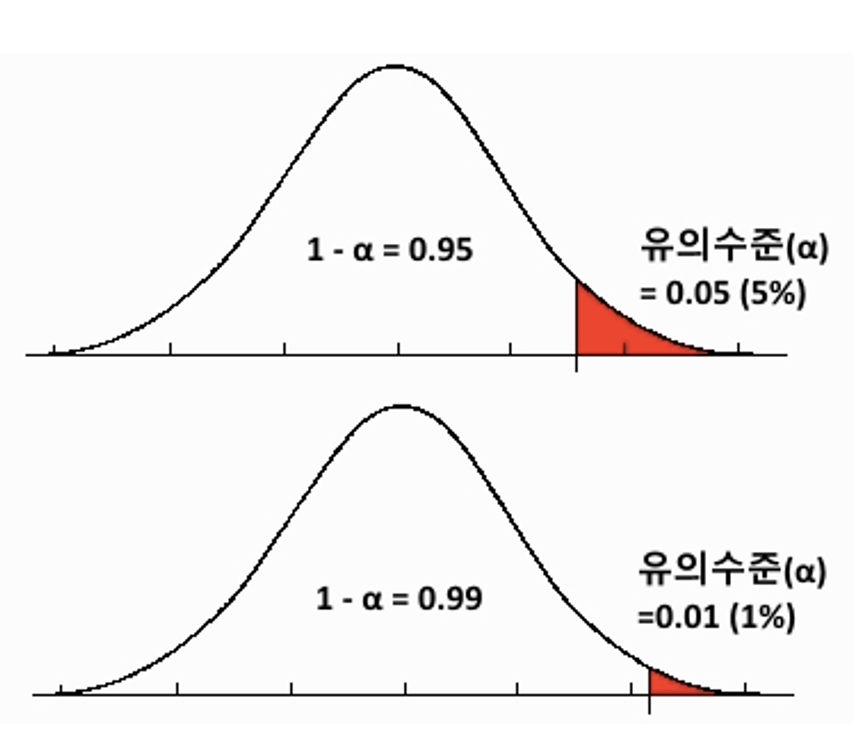
3. 유의 수준 설정하기
ㅇ 유의수준 = (귀무가설을 채택할 경우) 오류 허용 범위
: α로 표시하고 95%의 신뢰도를 기준으로 한다면 (1−0.95)인 0.05 값이 유의 수준 값이 된다.
유의 수준은 신뢰 수준의 반대 개념입니다. 즉 오류가 나타날 확률입니다. 보통 0.05를 사용한다.
확률값이므로, 역시 0부터 1 사이의 값을 가진다.
유의 수준 0.05로 설정 = 즉, 95% 신뢰도 기준
4. 검정통계량과 p-value
ㅇ 결과 해석 단계 1: 검정 방식 정하기 & 검정통계량 계산하기
- 이제 가설을 설정하고 유의 수준을 정했으니, 실험을 진행하고 실험 전/후 비교가 필요!
결론적으로 우리는 귀무가설을 채택할지, 기각할지 결정해야 함.
- 검정통계량이란 귀무가설을 채택 또는 기각하기 위해 사용하는 *확률변수를 의미
* 확률변수 : 특정 확률로 발생하는 각각의 결과를 수치값으로 표현하는 변수
[예시]
주사위를 던졌을 때 나오는 숫자를 확률변수 X라고 가정했을 때, 각 X에 대한 확률 P(X)를 구하시오.
→ 확률변수 X는 1,2,3,4,5,6
→ 주사위 값이 1~6 중 어떤 수가 나올지 모르기 때문에 우리는 이를 확률변수라고 명명
→ 각 X에 대한 확률은 1/6
- 검정통계량은 표본 평균, 비율, 상관 계수 간의 차이 등 다양한 형태를 취할 수 있으며, 검정방식의 선택은 가설과 데이터 종류에 따라 달라진다.
| 검정 방식 | 검정통계량 | 비교대상 | 대상DATA |
| Z 검정 | Z-value | 표본의 평균(차이 분석) 모집단의 분산을 알 수 있는 경우 | 연속형 자료 |
| T 검정 | t-value | 표본의 평균(차이 분석) 모집단의 분산을 알 수 없는 경우 | 연속형 자료 |
| 카이제곱검정 | x^2-value | 표본의 분산(상관관계 분석) | 범주형 자료 |
| F 검정 | F-value | 표본의 분산(상관관계 분석) | 범주형 자료 |
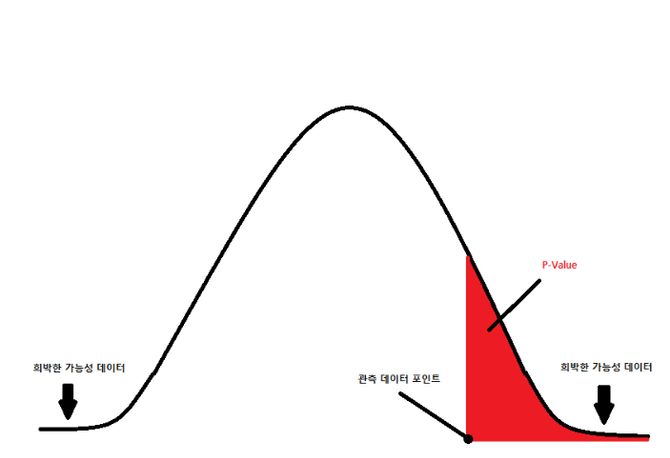
ㅇ 결과 해석 단계 2: p-value
- p-value : 어떤 사건이 우연히 발생할 확률(0~1 사이의 값)
- 유의 수준보다 p-value 가 작은 경우에 우연히 일어날 가능성이 거의 없어 대립가설을 채택하게 될 수 있다.
p-value가 0.05 보다 작다 = 우연히 일어났을 가능성이 거의 없다 = 인과관계가 있다고 추정 = 대립가설 채택
p-value가 0.05 보다 크다 = 우연히 일어났을 가능성이 높다 = 인과관계가 없다고 추정 = 대립가설 기각
- 1회 차에 학습했던 *중심극한정리를 통해, 모집단이 큰 경우 표본평균이 정규분포를 따르게 된다고 가정.
p-value는 정규분포 그래프에서 아래와 같이 확인할 수 있다.
- 정규분포의 그래프 아래쪽이 확률값이라는 사실을 기억하기!
- 유의 수준을 설정하고, p-value를 도출해서 의미를 해석한다는 점. 기억하기!
* 중심극한정리
: 표본수집을 기반으로 한 추리통계에서 모집단의 분포가 어떤 모양이더라도 모집단의 크기가 충분히 크다면 표본평균의 분포가 모수 기반의 정규분포를 이룰 것이므로 수집한 표본의 통계량을 이용해 모집단의 모수를 추정할 수 있도록 한다.
<요약>
ㅇ A/B 테스트라는 방법론을 통해 해당 과정에서 사용되는 통계개념을 학습
ㅇ 이는 가설설정, 통계적 의미 해석(P-value), 가설검정(T검정, 카이제곱검정)
ㅇ A/B 테스트는 5가지 단계로 진행. 현행데이터탐색 → 가설설정 → 유의 수준설정 → 실험 → 해석
ㅇ 귀무가설은 차이가 없거나 의미 있는 차이가 없는 경우의 가설.
ㅇ 대립가설은 차이가 있는 경우의 가설.
ㅇ 유의 수준은 신뢰도의 반대 개념.
ㅇ 오류의 허용 범위로 보통 0.05를 사용. 곧 신뢰도 95%를 의미.
ㅇ p-value는 어떠한 사건이 우연하게 발생할 확률.
ㅇ p-value가 0.05 보다 작다 = 우연히 일어났을 가능성이 거의 없다 = 인과관계가 있다고 추정 = 대립가설 채택
'[분석] 통계' 카테고리의 다른 글
| [세션] 통계학 라이브세션_1회차 (2) | 2024.06.03 |
|---|---|
| [강의] 통계학_기초(1) (0) | 2024.05.31 |